案例研究 - 應用知識庫 Part 1
應用知識庫 Part 1
進入客服情境後,我們應該要去匯總用戶的問題並去找到最適合的答案,本章節將延續飯店的案例,來示範建立飯店 QA 知識庫並檢索該知識庫的內容用於 AI 客服。
- Step 1:建立知識庫並上傳FAQ檔案
- Step 2:使用LLM Completion產生檢索的關鍵字
- Step 3:Push Message
- Step 4:Retrieve Knowledge
- Step 5:Push Message
- Step 6:預覽 Bot
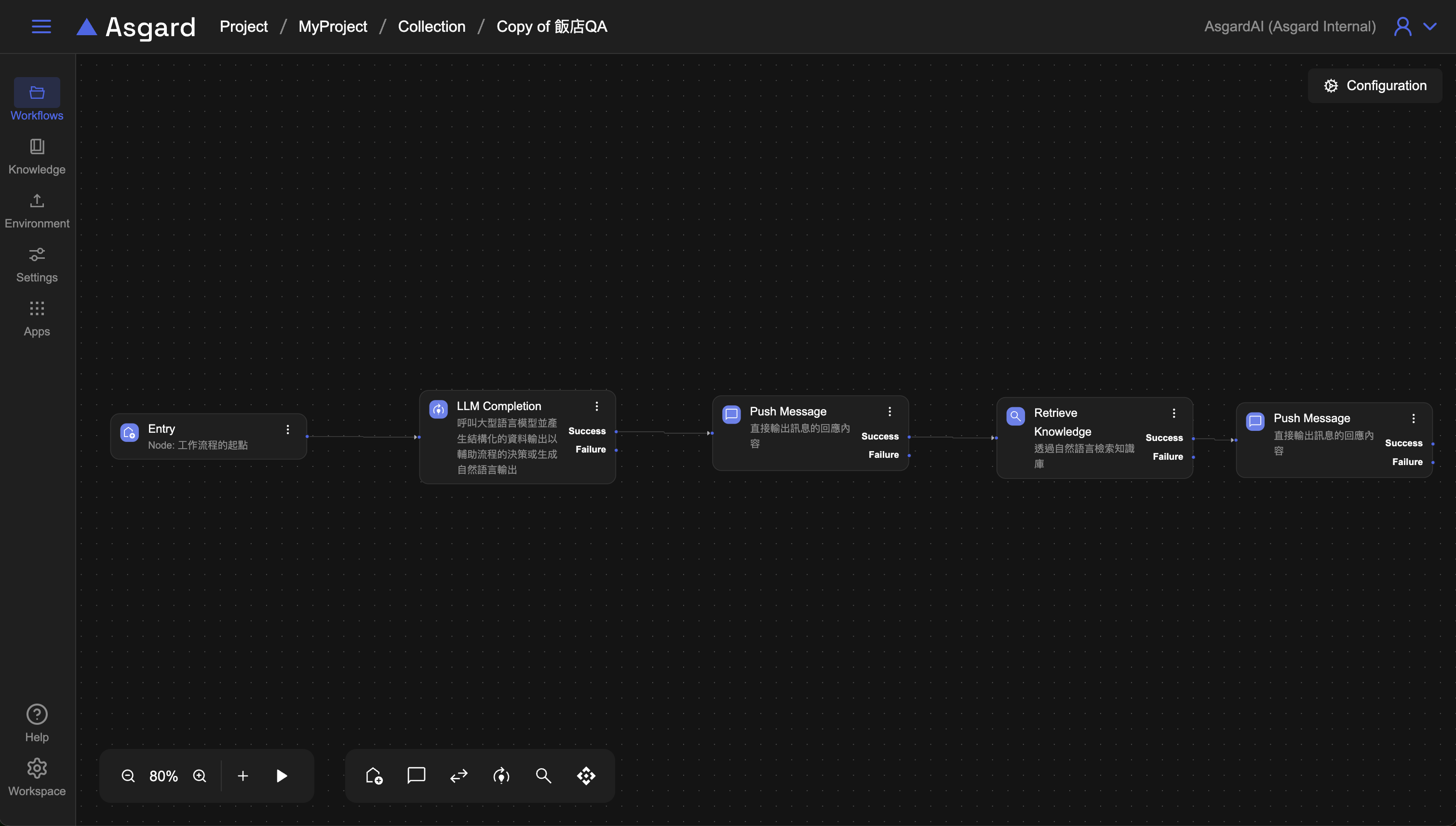
Step 1:建立知識庫並上傳FAQ檔案
Step 1-1:建立知識庫
在左側的功能列點擊 Knowledge,這邊是知識庫(Knowledge Base)的功能,操作就像資料夾一樣簡單,首先我們先為飯店 QA 的 AI 客服建立一個專用的知識庫,點擊「Add New Knowledge Base」新增一個空白的知識庫。
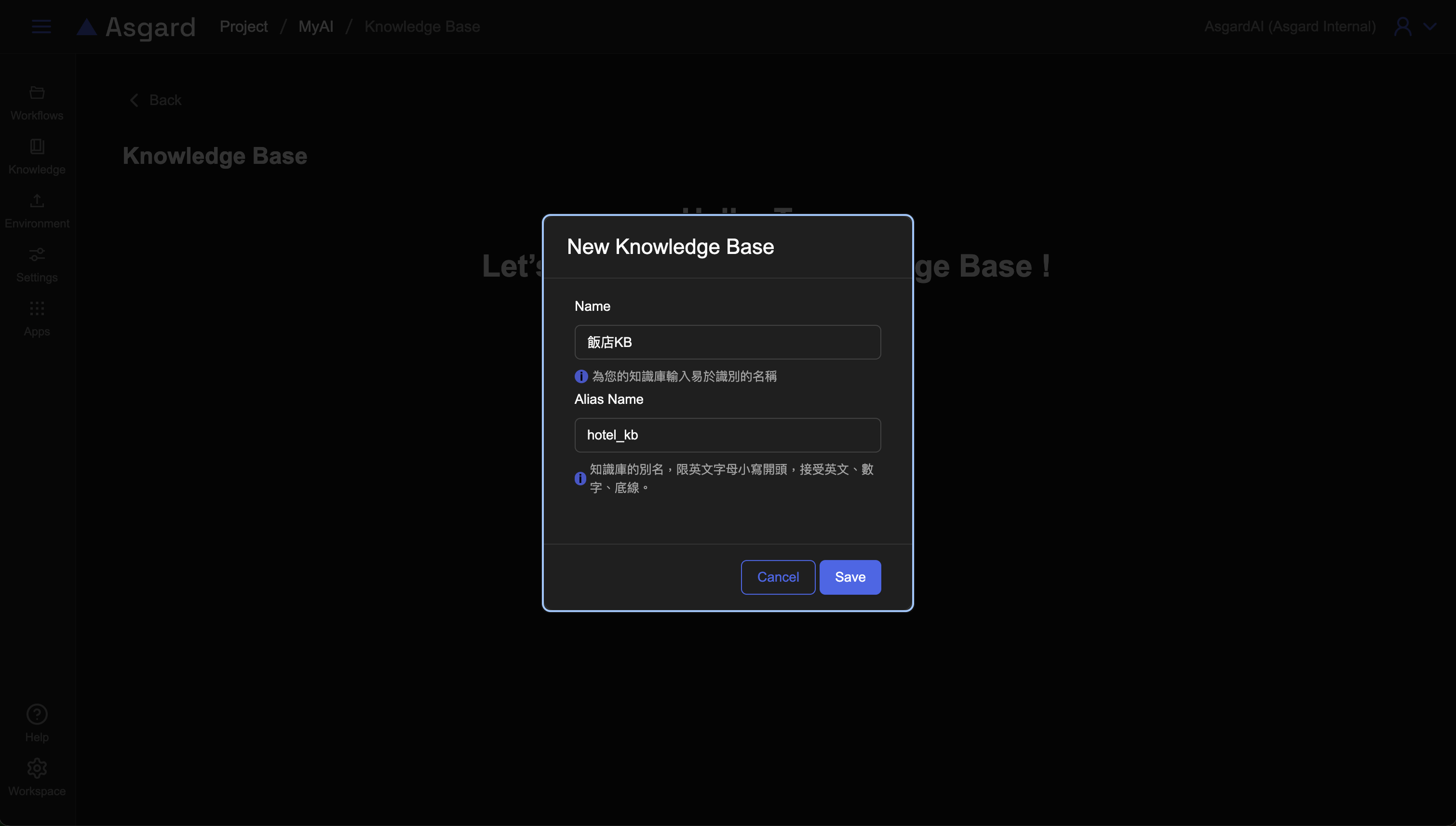
輸入名稱(Name)與知識庫別名(Alias Name),別名限英文字母小寫開頭,接受英文、數字、底線的組合。
此處我們輸入飯店KB與hotel_kb易於識別。
成功建立新知識庫
空白的知識庫包含了 Files 與 Tags
Step 1-2:匯入檔案
點擊右上方的「Add」選擇 xlsx 類型檔案以繼續上傳。
Import File
按照步驟指示選擇要上傳的檔案並點擊下一步
Processing
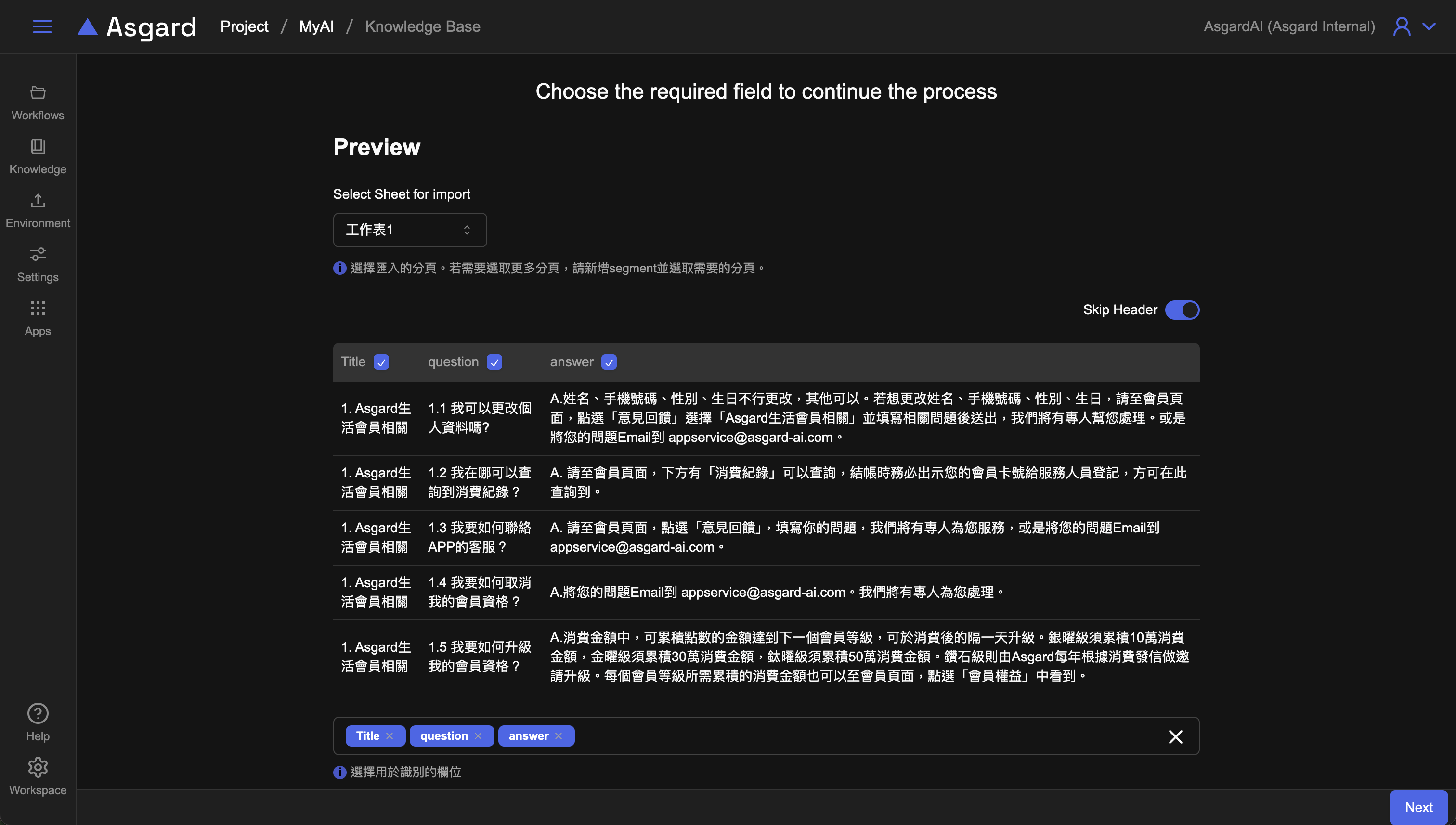
匯入 xlsx 檔案前可先預覽並設定分段,分段是決定文件如何處理的方式。
- 選擇匯入的工作表分頁。若需要選取其他更多分頁,可後續新增
segment並選取需要的分頁,此處先選擇工作表 1並繼續。 Skip header設定是否跳過資料的第一列。假如第一列為標題列,此處可以勾選Skip header,若第一列就是資料列,建議不要勾選Skip header。- 勾選需要匯入的欄位。
- 選擇用於識��別的欄位。當文件沒有
primary key時,建議此處全選,範例檔案中為title+question+answer。識別的欄位會作為後續Enhancement的計算。
Finish
完成匯入檔案與分段(Segment)設定
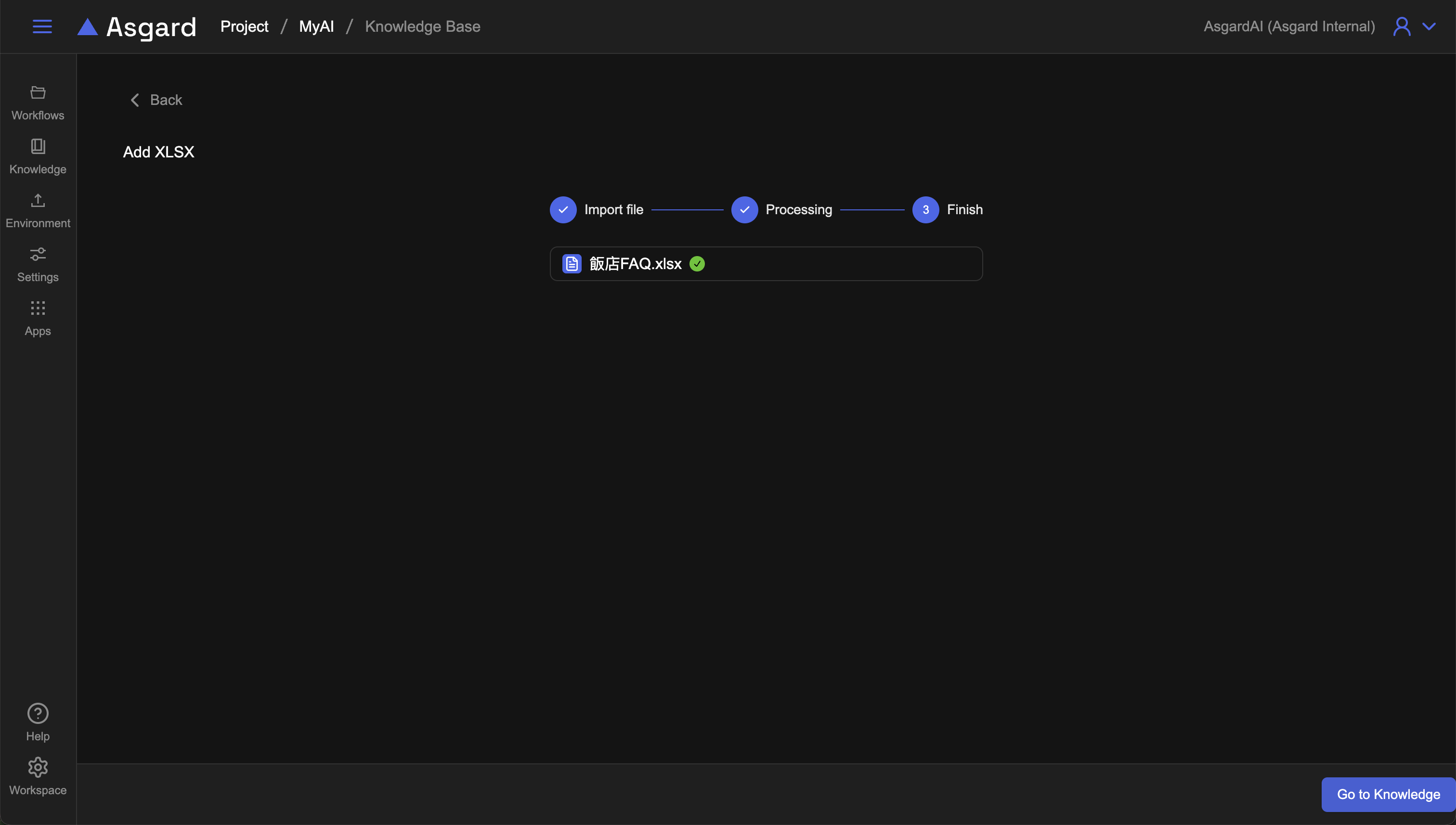
回到檔案列表時,可以看到剛剛上傳的檔案正在處理中,請靜待系統處理檔案完成,完成後狀態會由 Processing 變成 Ready,代表該份文件已經被系統處理完成,知識已經可以被 AI 所使用。
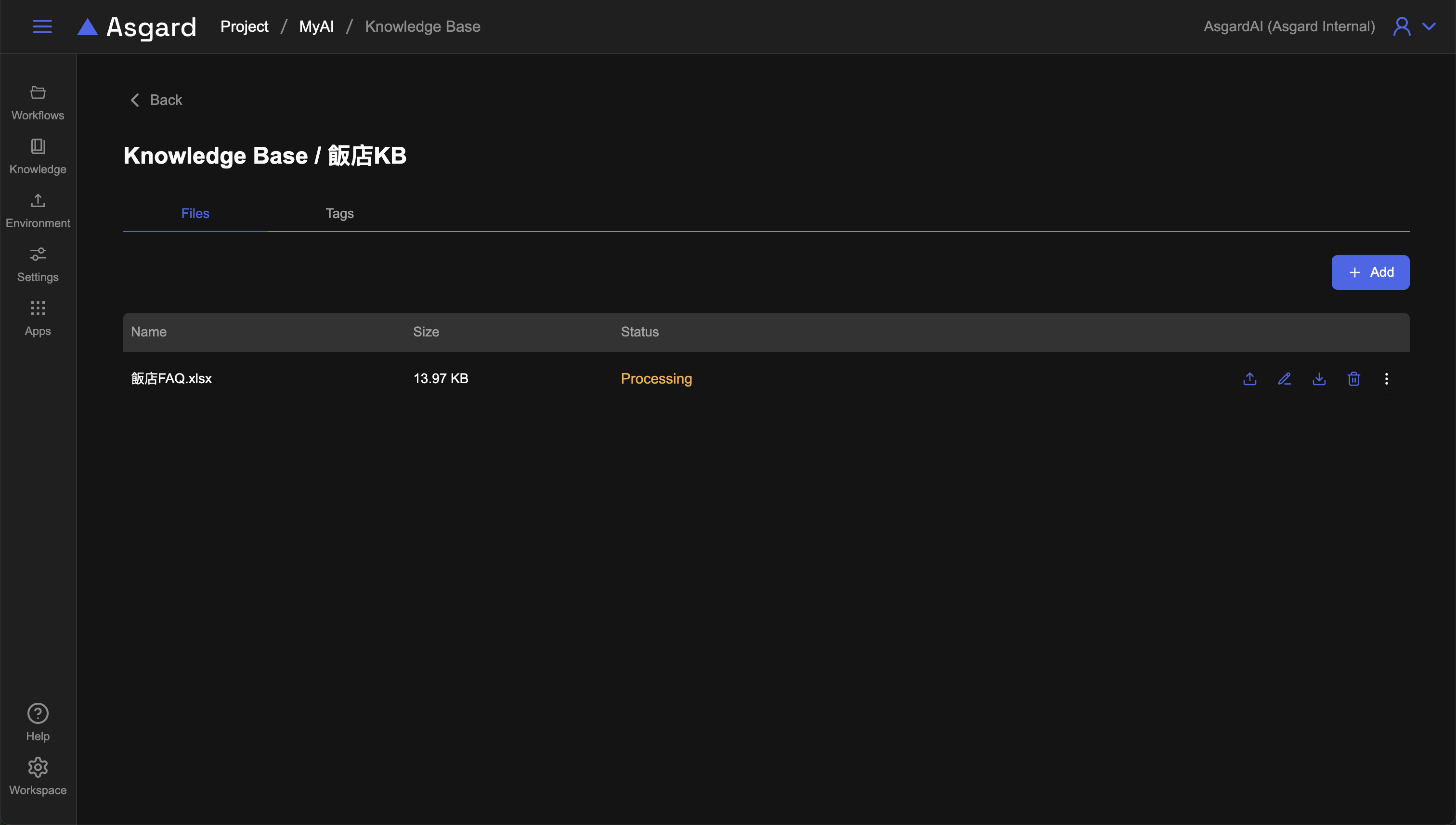
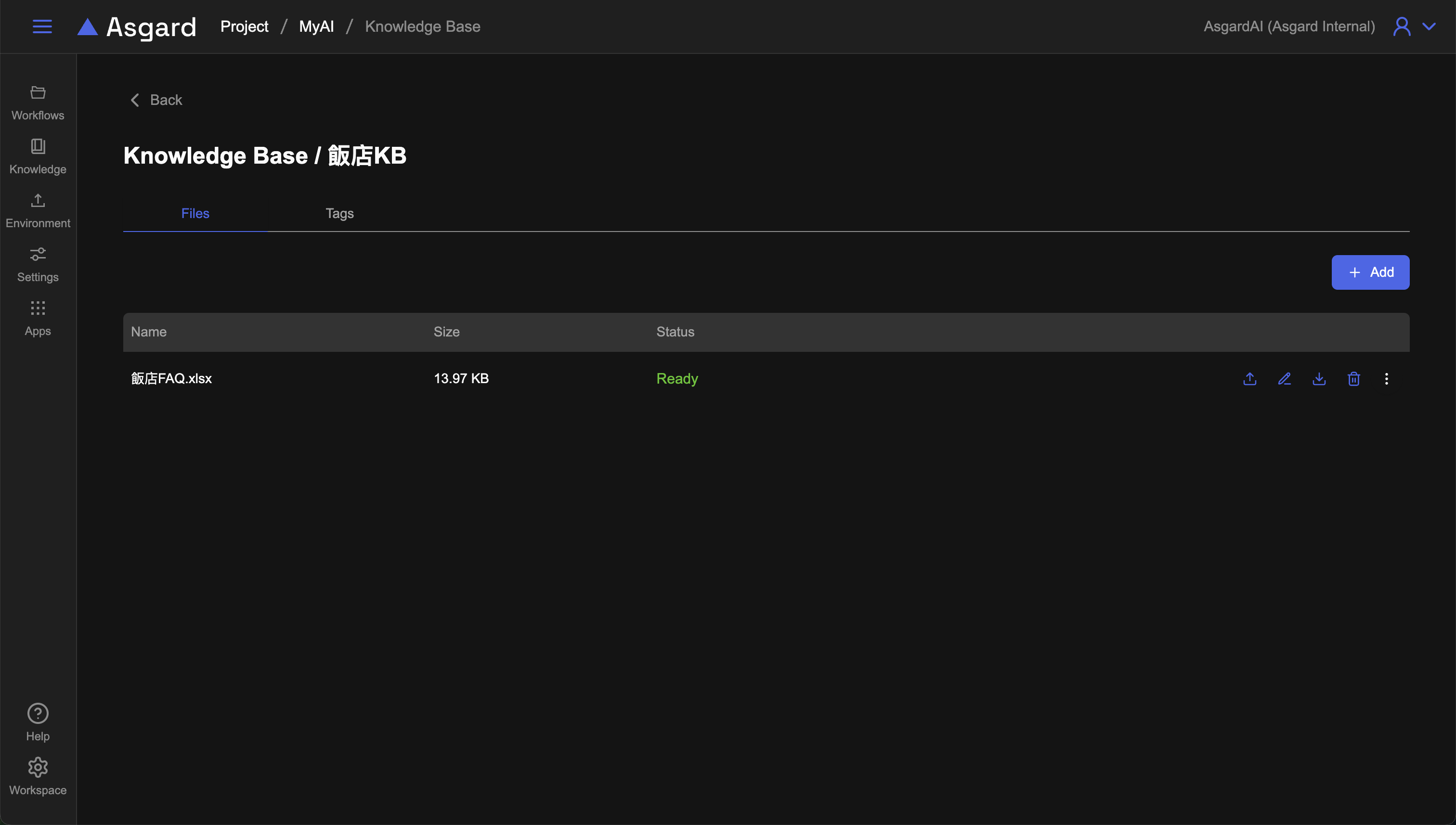
Ready 的狀態
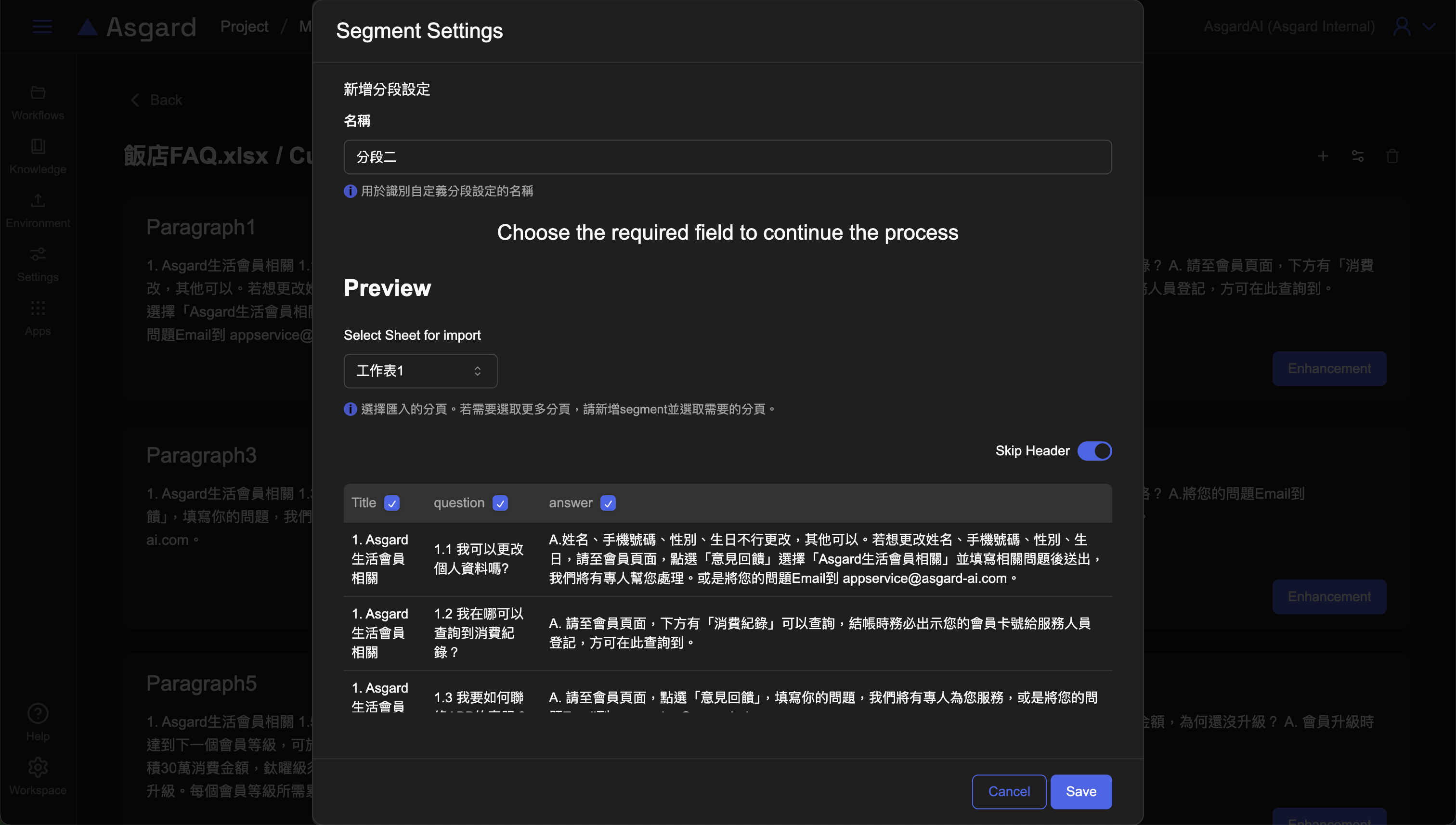
Step 1-3:檢視檔案與增強分段說明
增強(Enhancement)有三種類型:
- Supplement:用於補充說明該知識。
- Question問題:選擇的該分段知識如為問題,可以去新增 enhancement 作為該問題的不同問法。
- Answer答案:選擇的該分段知識如為問題,可以去新增 enhancement 作為該問題的其他不同的回答方式。
- Tag:用於篩選。
其他功能說明
- Upload 重新上傳,用於既有檔案資料的更新,比如原有50筆,新增到60筆時可以使用此上傳功能,套用相同的分段設定,不需要重新操作。Enhancement 會根據適當的 primary key 去 migrate 到新的檔案版本,不會消失。
- 下載檔案
- 刪除檔案
- 新增分段設定,若 xlsx 有其他分頁,可以在此新增新的分段設定並選擇其他分頁,操作與匯入時相同。
若檔案有多個以上的分段,可以在上方的 Current Segment 切換檢視。
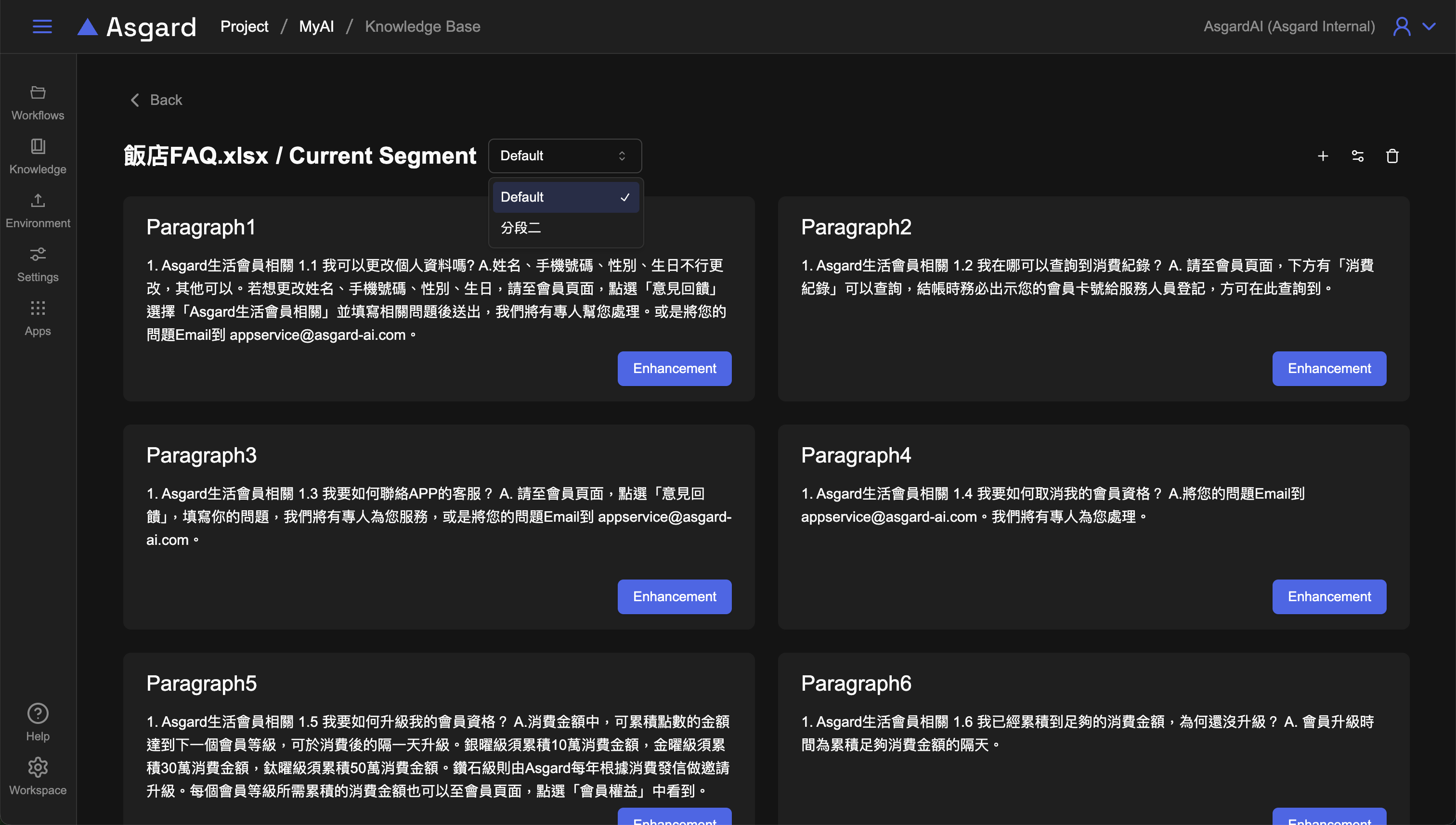
Step 2:使用 LLM Completion 產生檢索的關鍵字
LLM 呼叫 LLM 來產生用於知識庫檢索的關鍵字。
- Completion Model 選擇已經設定好的大型語言模型,或是可以點擊
「Add」以新增 Completion Model 設定。 - Prompt 選擇
Template(Advance)並輸入以下範例請求 AI:
你是飯店的客服助手,每當客戶向你提出問題的時候,你都會先思考應該要輸入哪些`關鍵字句`到飯店的 FAQ 搜尋引擎進行搜尋相關的知識。你的目標是找出最合適的`關鍵字句`
* 由於飯店的 FAQ 搜尋引擎採用了先進的語意搜索模式,因此這些`關鍵字句`可以是多個同義的單詞或是多句同義的句子,你會盡可能的想出最能搜尋到符合客戶提問的知識。
* 這是你跟客戶過去的對話紀錄:
```
{{{history historyStart -1}}}
```
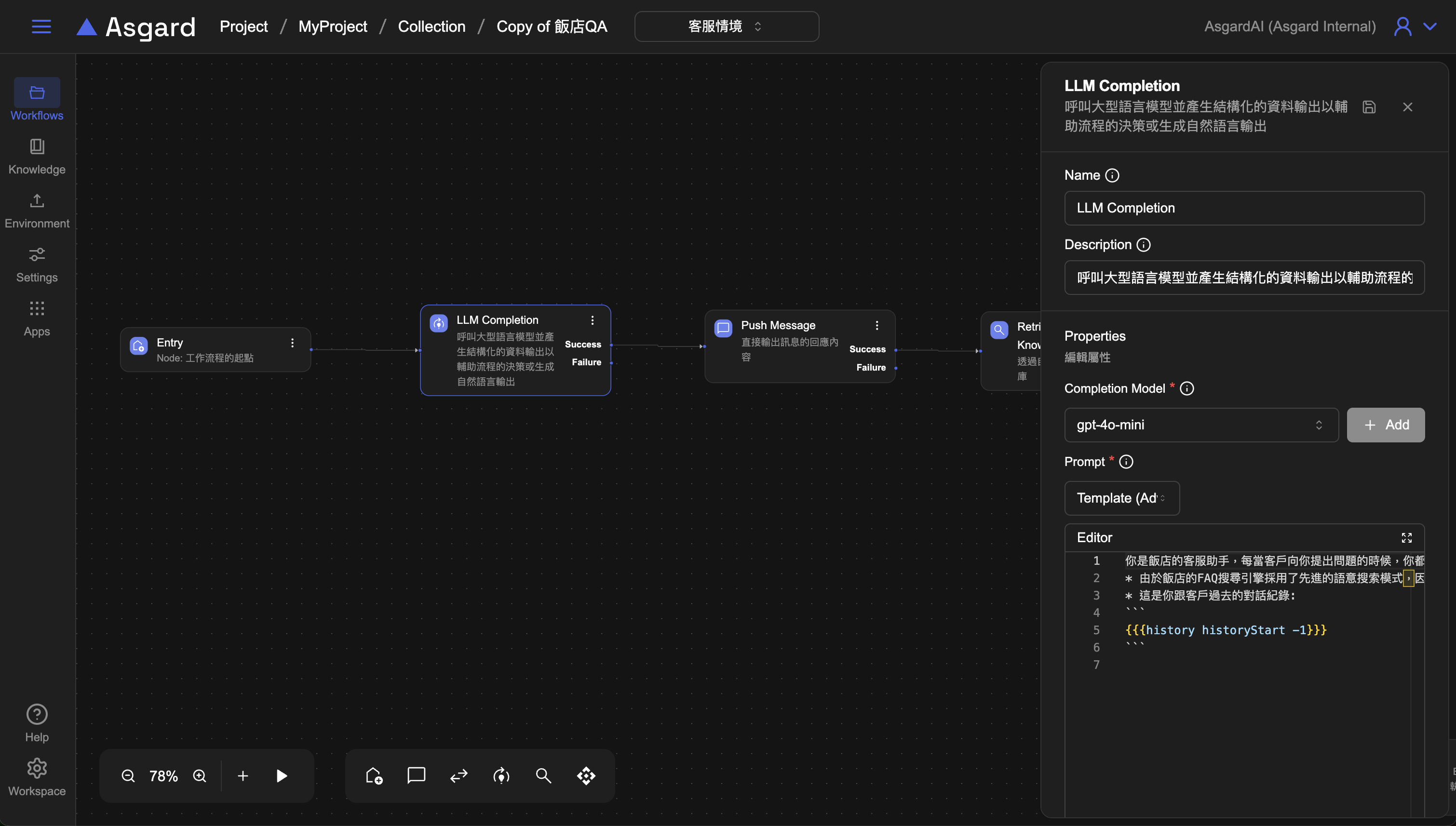
- Output Schema
searchQuery 用以存放 LLM 產生的關鍵字句。
question 多輪問答,保留前一個問題的欄位。
{
"type": "object",
"properties": {
"searchQuery": {
"type": "string",
"description": "searchQuery 是你經過思考後,你認為最適合拿去 FAQ 知識庫搜索的 1 ~ 3 個關鍵字句"
},
"question": {
"type": "string",
"description": "question 以第一人稱問句的形式彙整了客戶主要想問的問題"
}
},
"required": [
"searchQuery",
"question"
]
}
詳細 JSON Schema 寫法,請參考JSON Schema
- MaxTokens 設定消耗 Token 上限,此處選擇
Literal 類型並填入4096。Token 上限請依據選用的模型支援的範圍去設定,此處僅為範例。 - 儲存設定
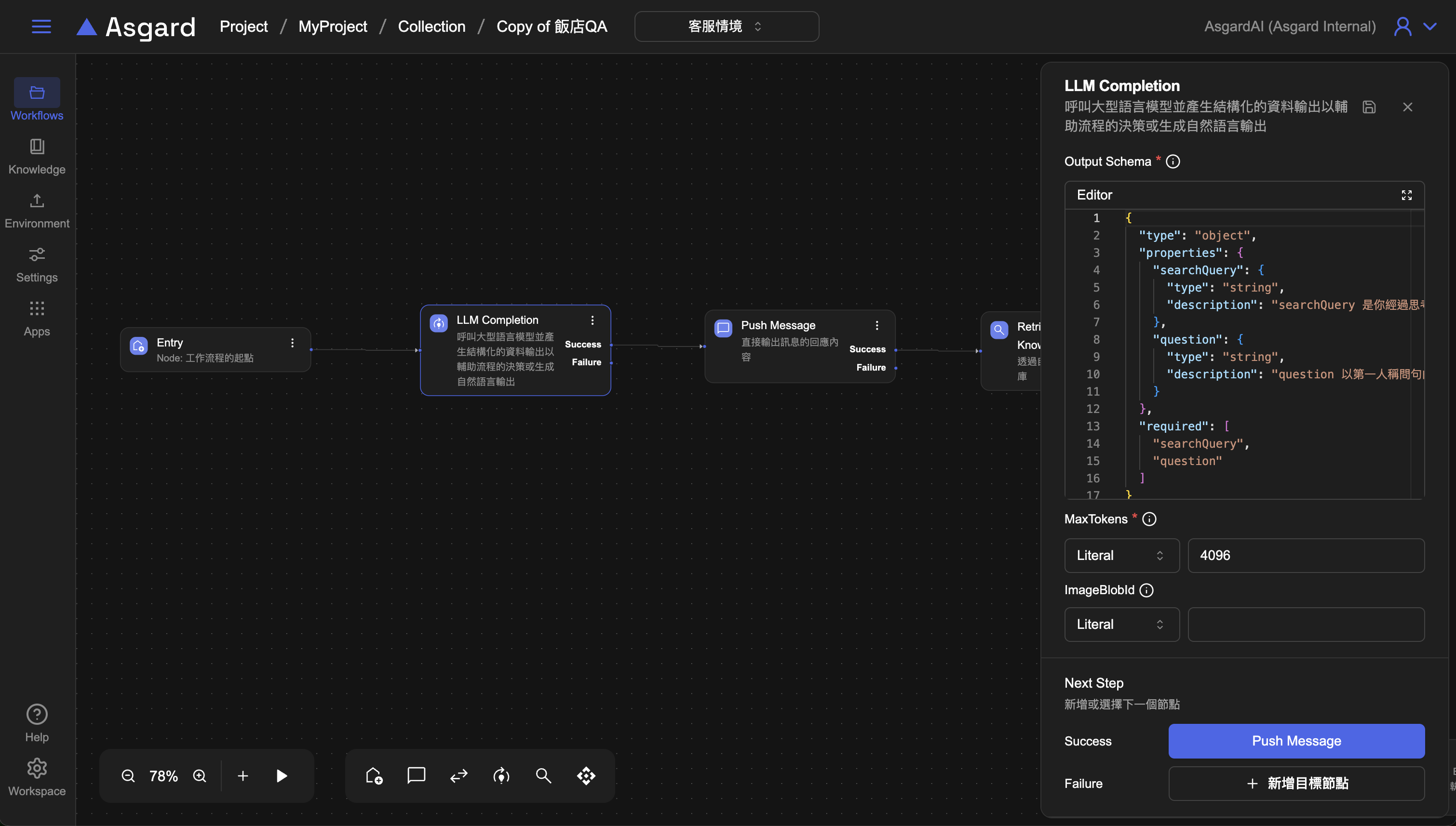
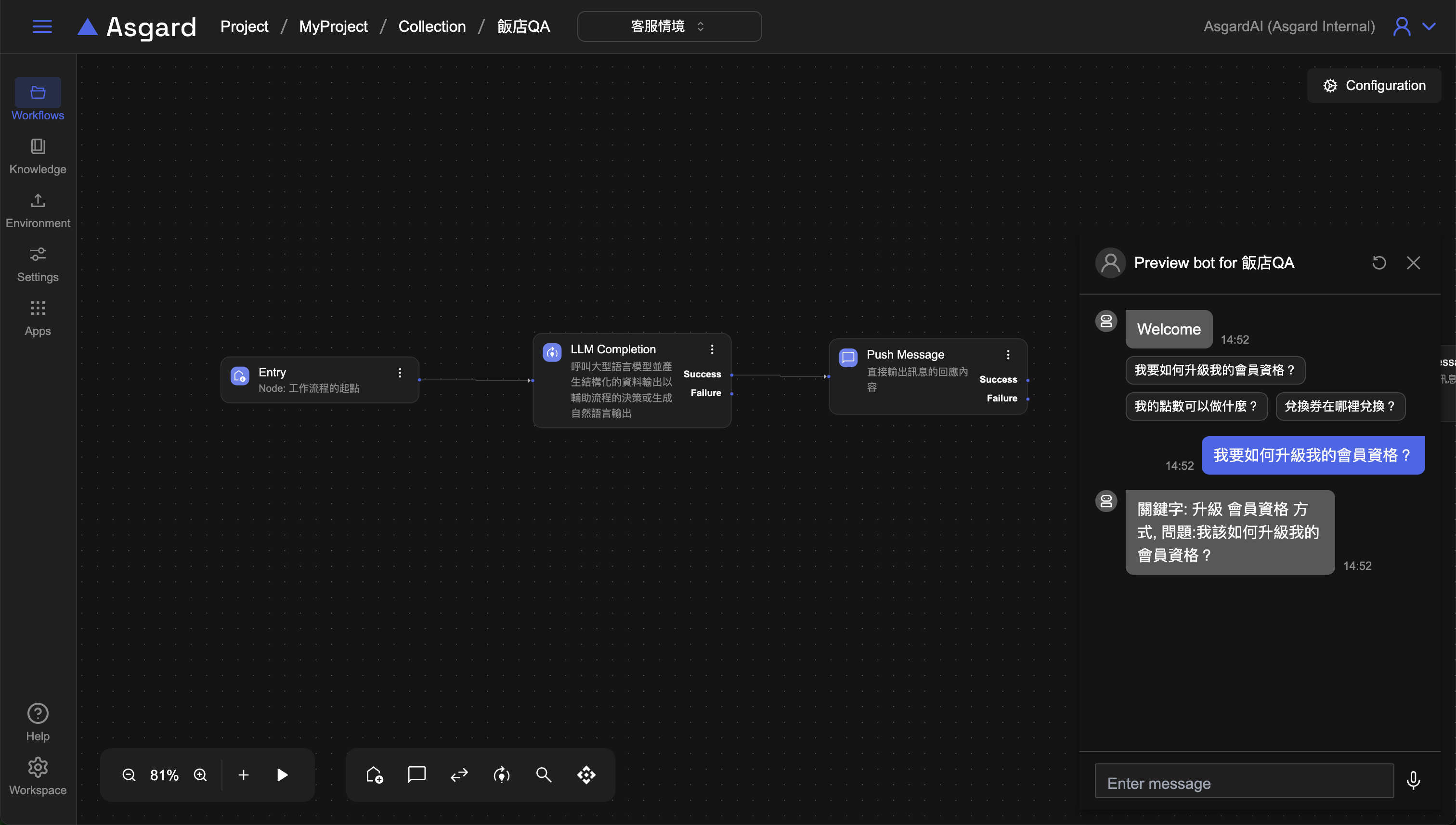
Step 3:Push Message
將 LLM 生成的內容使用 Push Message 印出來。
- Message 選擇
Expression的類型,並輸入底下範例 - Optional: 可以將
Processor的Description改成容易識別的描述幫助�工作流程的編排易讀性,例如改成「產生的關鍵字句」 - 儲存設定
(() => {
// return the result of the expression
return "關鍵字: " + searchQuery + ", 問題:" + question;
})()
可先預覽一下目前產生的關鍵字句是什麼,是否有如預期的生成。
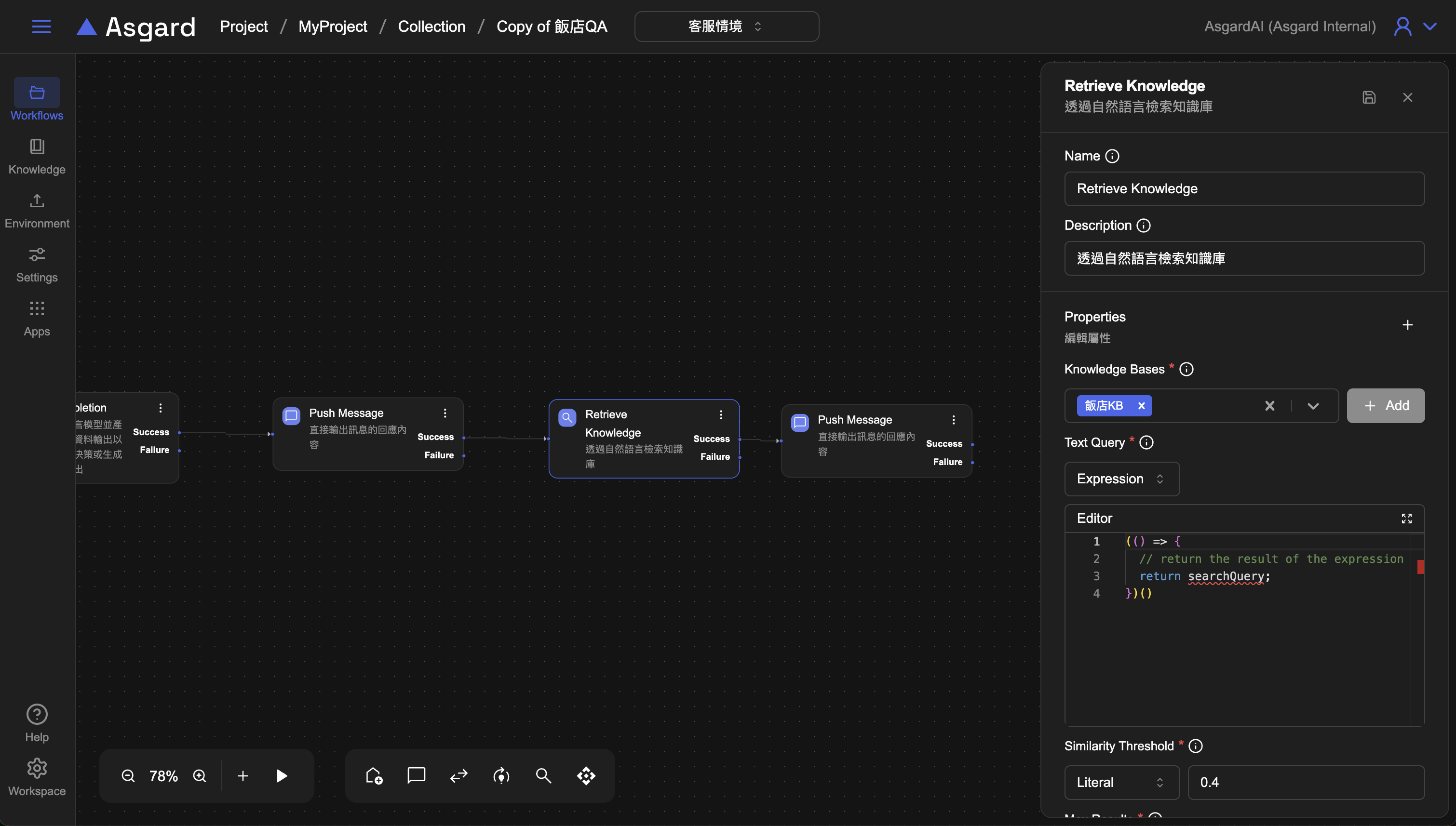
Step 4:Retrieve Knowledge
將生成的關鍵字用於檢索知識庫。
- Knowledge Base 選擇第一步時建立並匯入好檔案的知識庫,或是可以點擊
「Add」以新增知識庫設定,注意知識庫內記得匯入檔案。 - Text Query 用於檢索的關鍵字句,可以放剛剛建立的 searchQuery
(() => {
// return the result of the expression
return searchQuery;
})()
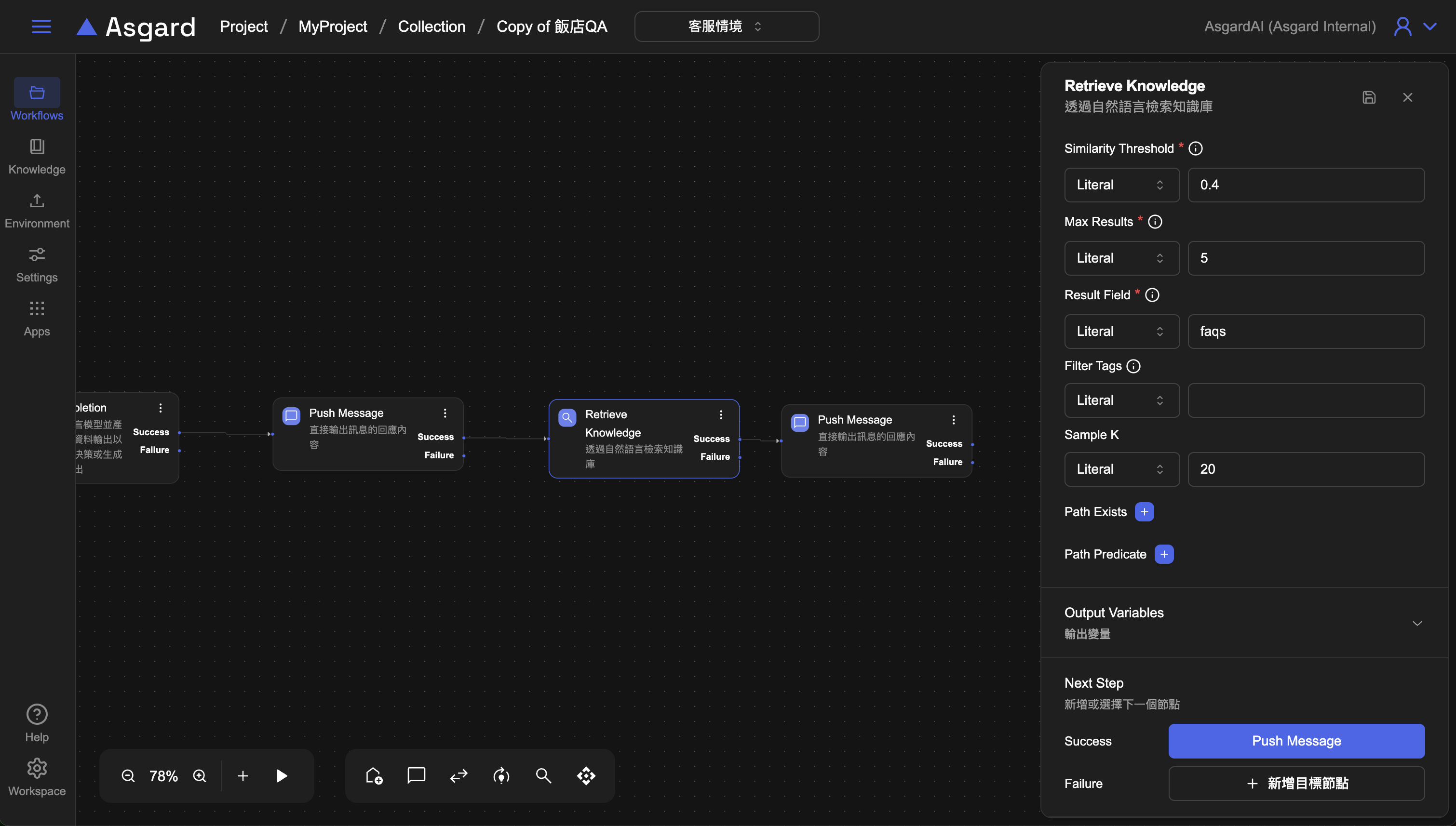
- Similarity Threshold 填入 0 ~ 1 之間的數字,
1代表最相似,以此遞減。範例使用0.4這個數值。 - Max Results 最多回覆幾筆,可以根據資料量與筆數來判斷,範例使用
5表示最多回覆 5 筆。 - Result Field 儲存結果的變數陣列,範例使用
faqs來儲存。 - Filter Tag 可以過濾增強的 Tag。
- Sample K 預設
20。
Step 5:Push Message
將 Retrieve Knowledge 的內容使用 Push Message 印出來。
- Message 選擇 Expression 的類型,並輸入底下範例
- Optional: 可以將 Processor 的 Description 改成容易識別的描述幫助工作流程的編排易讀性,例如改成「retrieve content」
- 儲存設定
(() => {
// return the result of the expression
return JSON.stringify(faqs);
})()

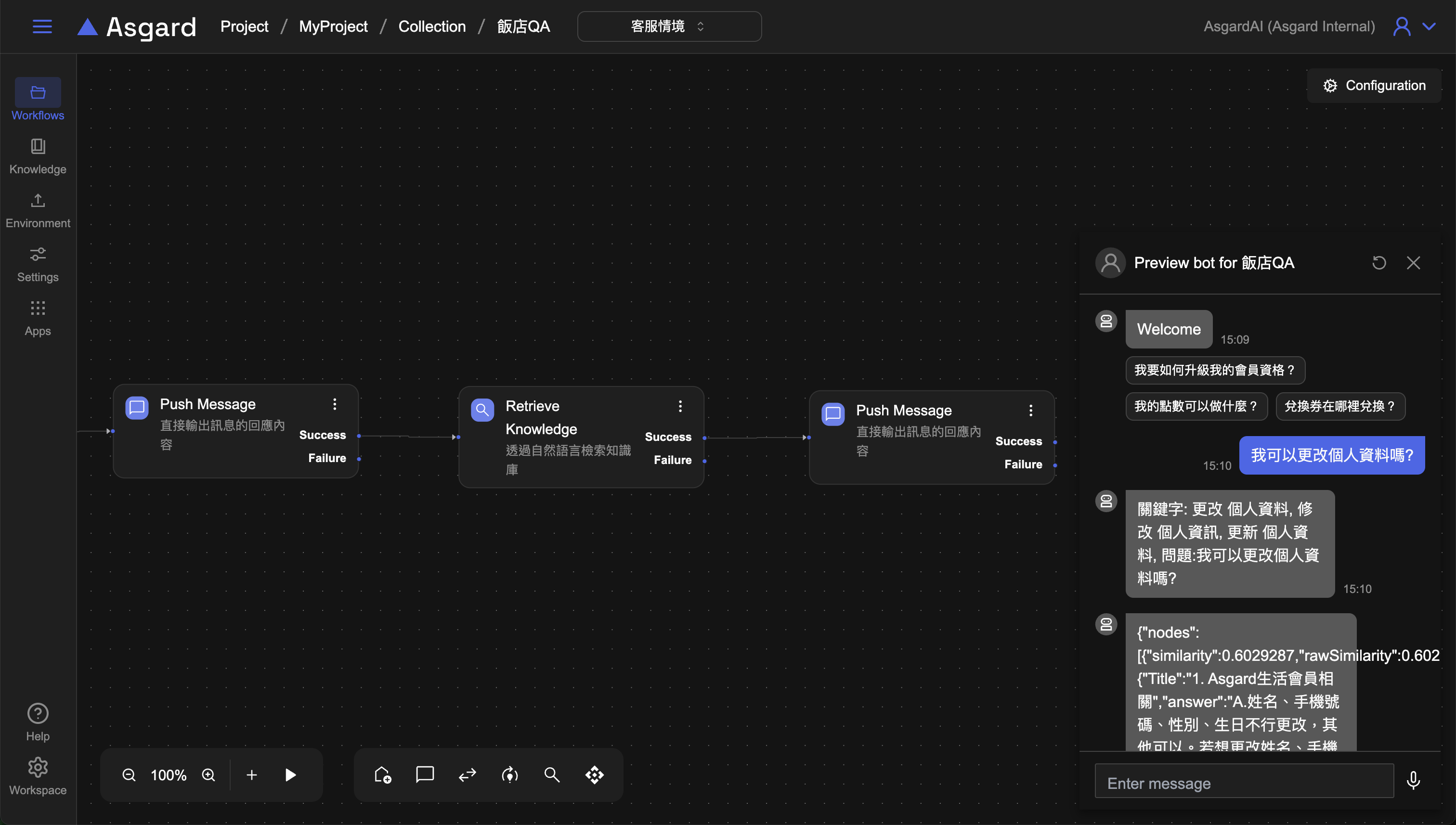
Step 6:預覽 Bot
點擊 Preview 來預覽工作流程是否有檢索到對應的問題回答。當用戶問了與知識庫相關的問題時,AI 應該要能精準搜尋到對應的回答。
▶️ 下一步
可能會有 AI 找不到回答的情境
因此 Part 2 的範例我們會加上 Router、Update Context、Stream LLM Completion Message 去處理不同路徑的流程,近一步完善 Workflow。