Automation Tool
Asgard 提供了不同的 workflow 建立類型,本章介紹 Automation Tool 類型的workflow。
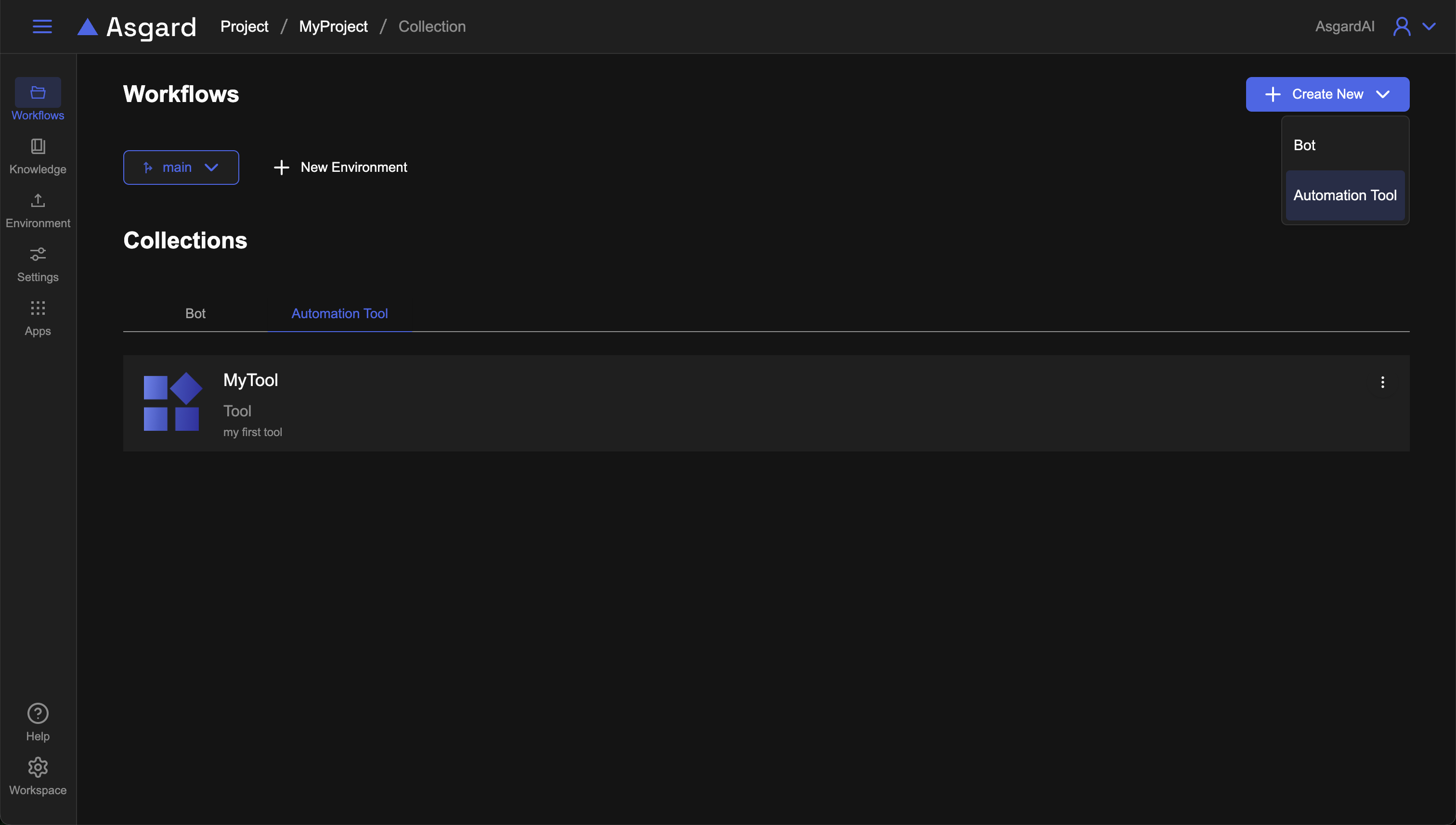
1 建立新的 Automation Tool
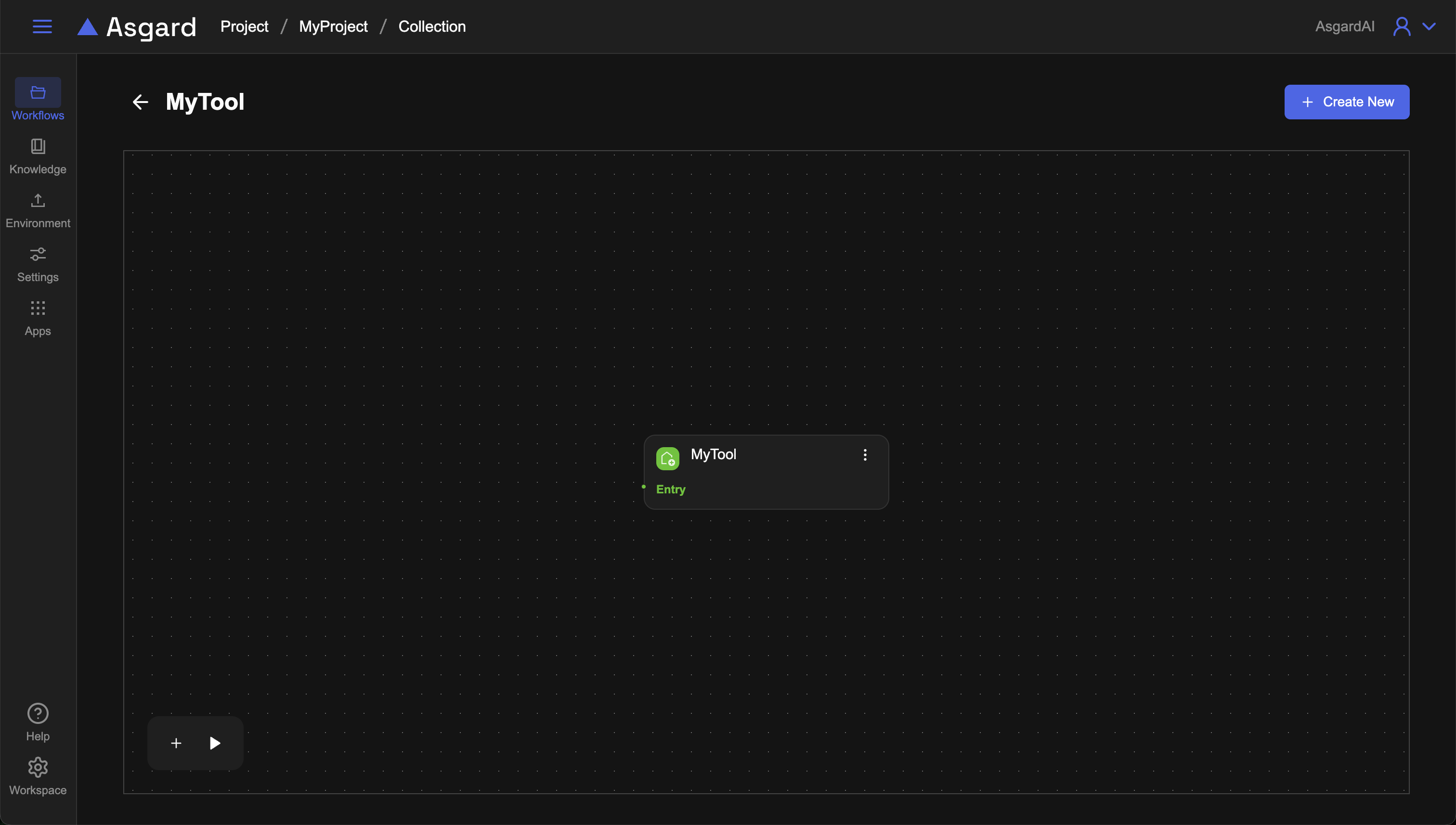
選擇 Project 進到該 Project 的 Collections 頁面,點擊右上方「Create New」選擇 Automation Tool 類型建立,輸入名稱與描述建立後,可以在 Automation Tool 看到剛剛新建的 MyTool,點擊進入 workflow sets 頁面,可以看到 Asgard 已經預設幫您建好了初始的 workflow,點擊該 workflow 進入 workflow 工作區。
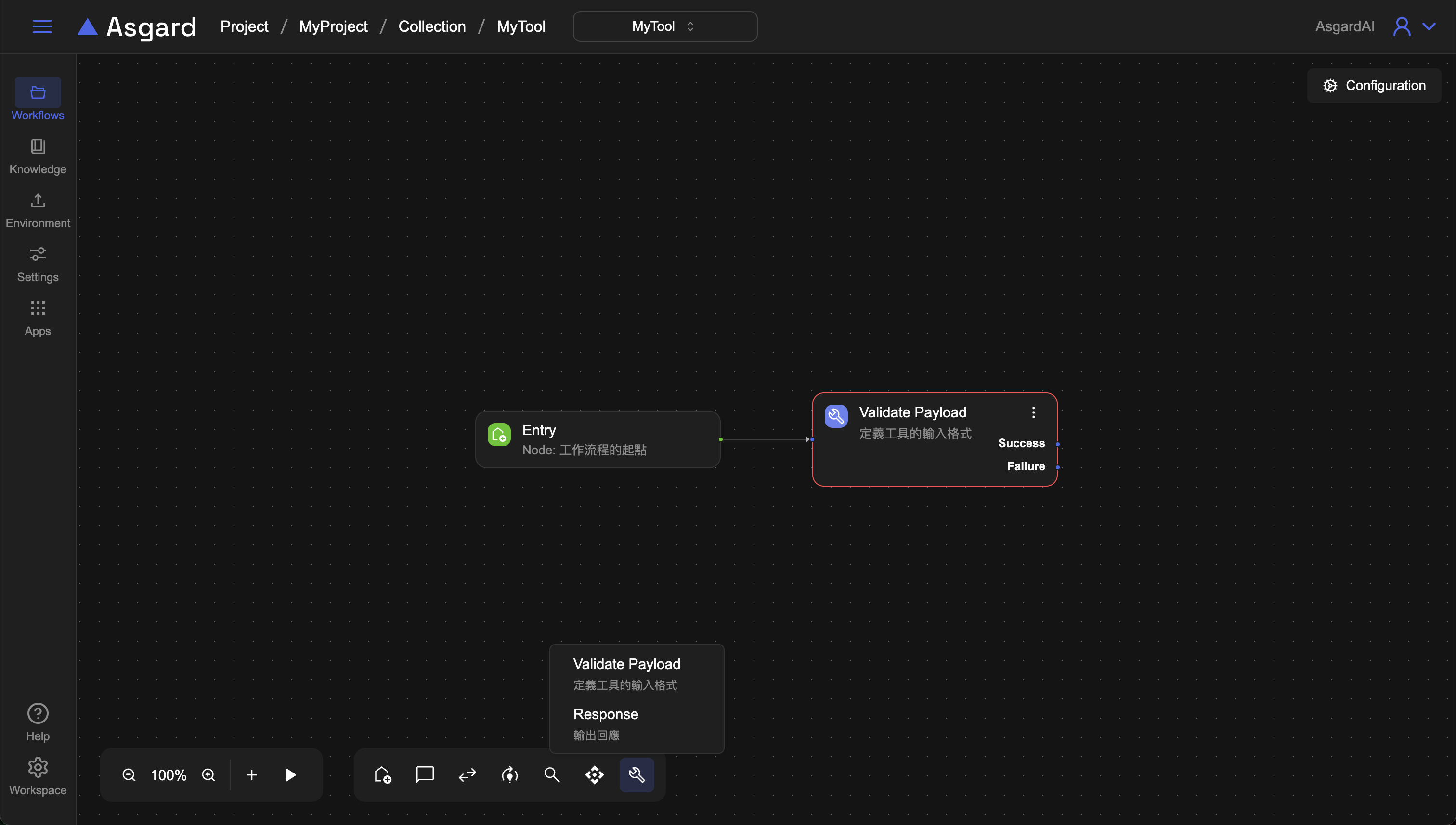
2 編排 workflow
Automation Tool 與 Bot 的區別在於,Automation Tool 多了專屬的 processors: Validate Payload與Response,讓用戶可以快速拖拉建立 API。新增 Automation Tool 時,Asgard 預設會為您建好初始進入節點與 Validate Payload 節點,節省建立時間。Validate Payload 用於驗證 input,Response 則是用來放 output 的結果。
3 範例:使用 Automation Tool 存取 API
此範例將使用 DummyJSON 的 To Do API 來實際存取 API 並拿到 To Do 清單的項目。整個範例會建立 3 個 Processor 來完成存取 API 的流程,最後藉由預覽來驗證功能。
3-1 Validate Payload
在 Schema 輸入需要驗證的 JSON Schema,此處依照 API 需要傳 To Do 的 id。
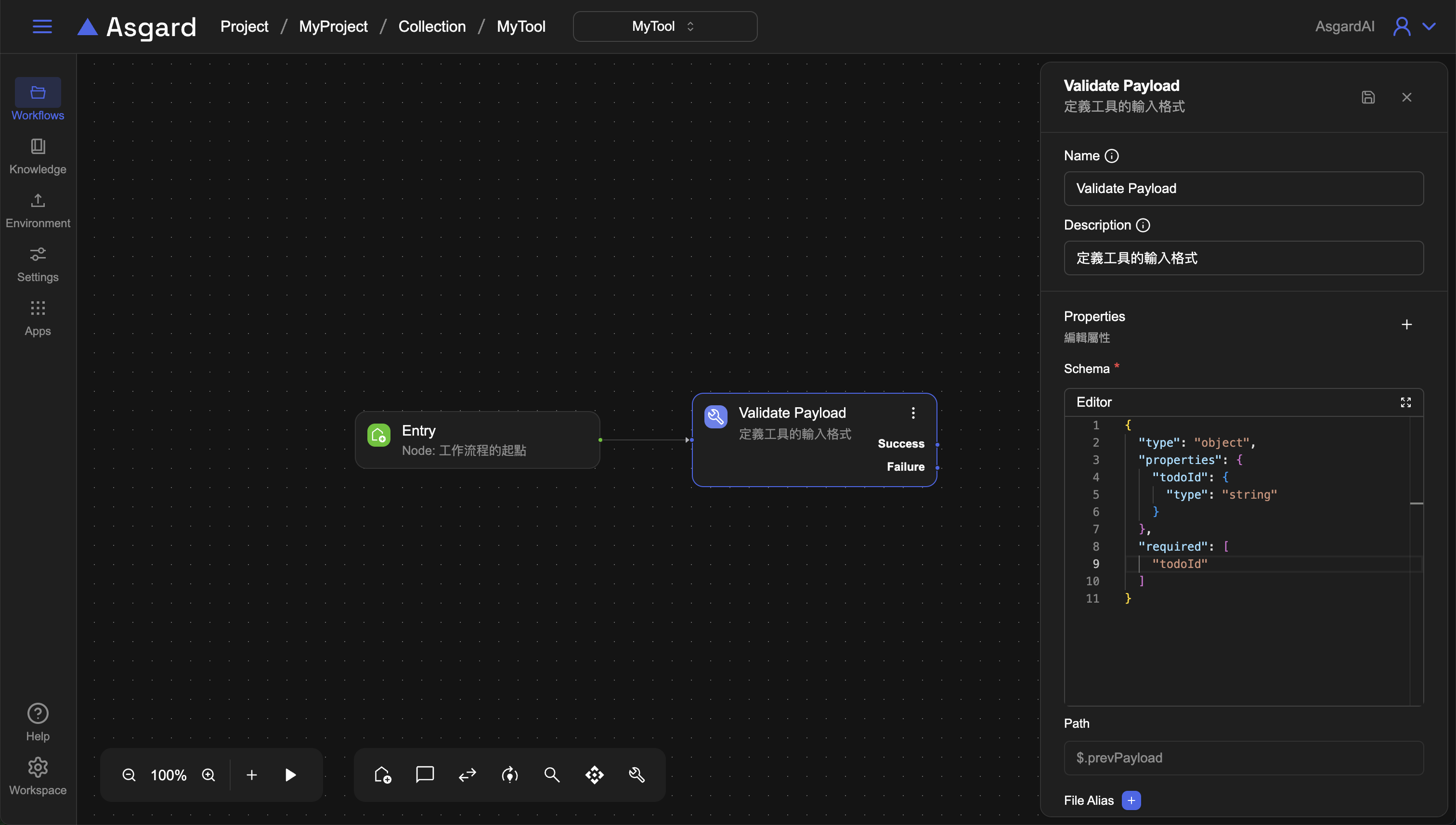
詳細 JSON Schema 寫法,請參考JSON Schema
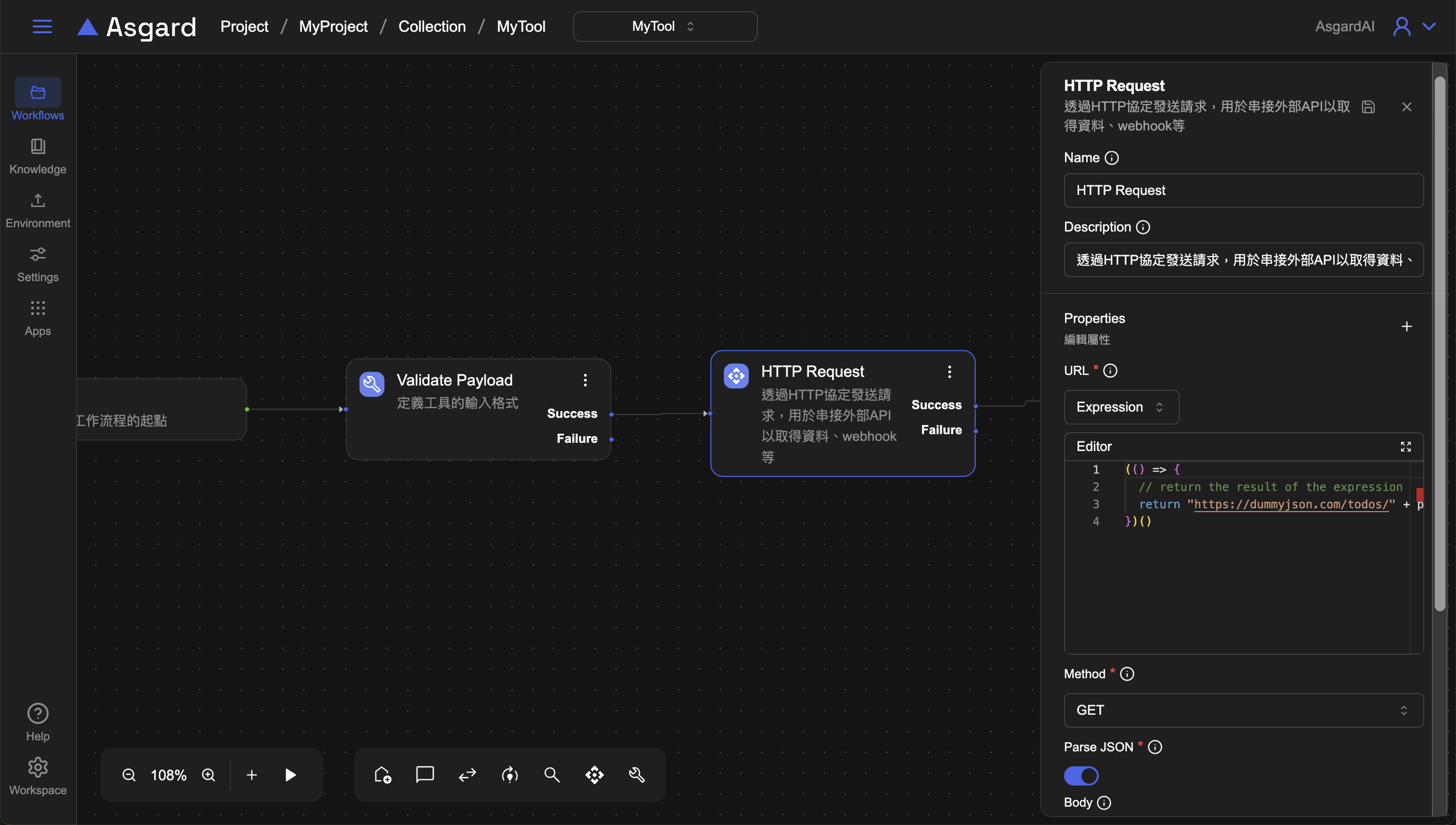
3-2 Http Request
URL 處選擇 Expression 並填入 URL,這個範例需要傳入 To Do 的 id,因此在 URL 最後加上剛剛在 Validate Payload 定義的 todoId:
prevPayload.todoId
(() => {
// return the result of the expression
return "https://dummyjson.com/todos/" + prevPayload.todoId;
})()
Method 請選 GET,Parse JSON 請啟用,才能將回傳的資料以JSON格式進行解析。
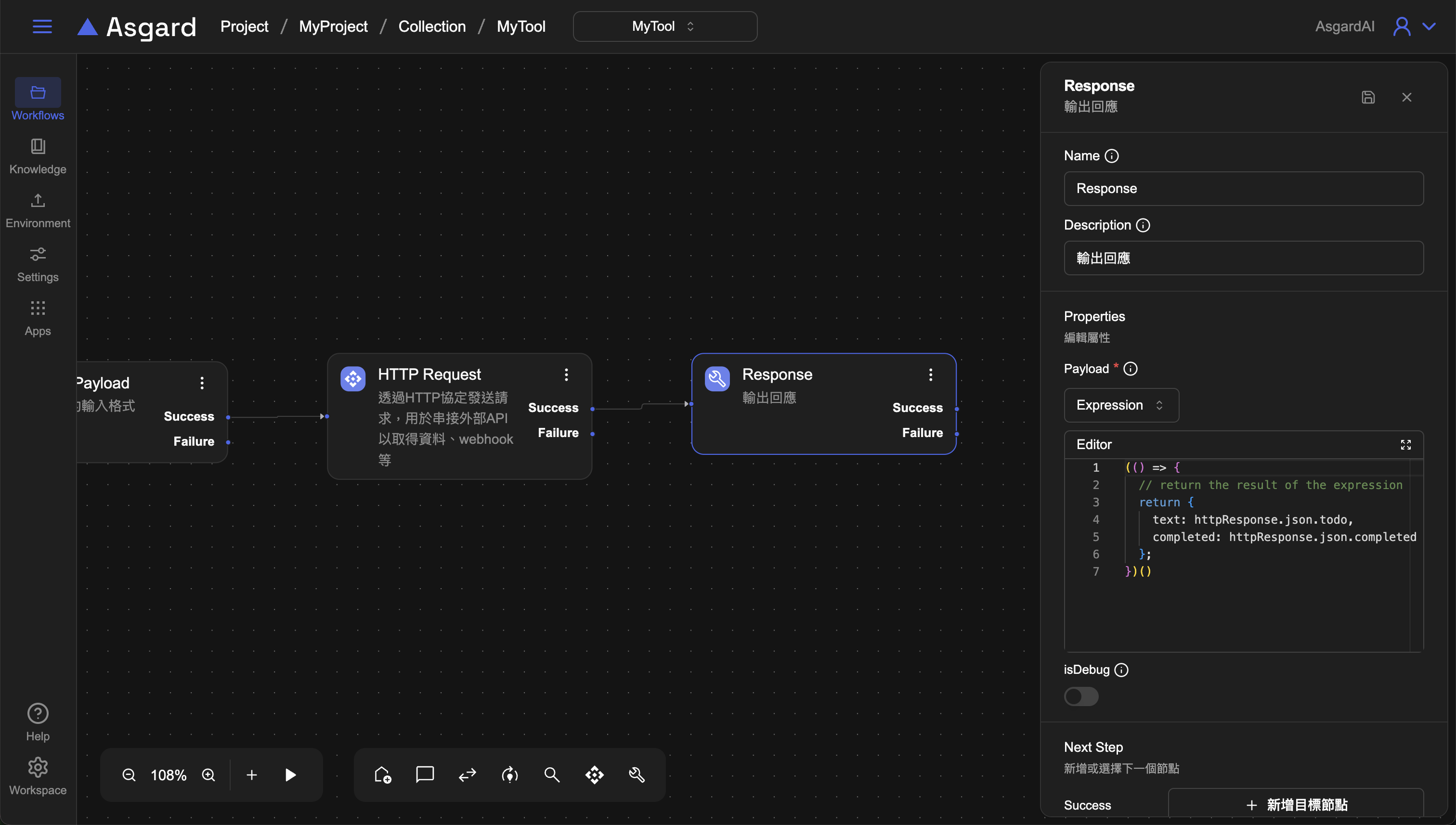
3-3 Response
利用 Payload 屬性輸出與訊息對應的結構化資料。選擇 Expression 並填入以下範例。
(() => {
// return the result of the expression
return {
text: httpResponse.json.todo,
completed: httpResponse.json.completed
};
})()
3-4 預覽
預覽 Automation Tool 點擊 preview 來實際存取該 API 測試,類型請選 JSON,在 Body 的地方,可以看到剛剛規定需要輸入的 to do id,此處輸入「1」後點擊 Send。底下 Response Body 可以成功拿到該 to do 清單的第一項:
"Do something nice for someone I care about"
4 範例:使用Automation Tool上傳圖片並辨識影像
此範例會讓用戶上傳一張圖片,並讓 AI 依據用戶的問題加上圖片去回答。整個範例會建立 3 個 Processor 來完成辨識影像的流程,最後藉由預覽來驗證功能。
前置作業:
- 可以支援辨識影像的 Completion Model
- 一張圖片
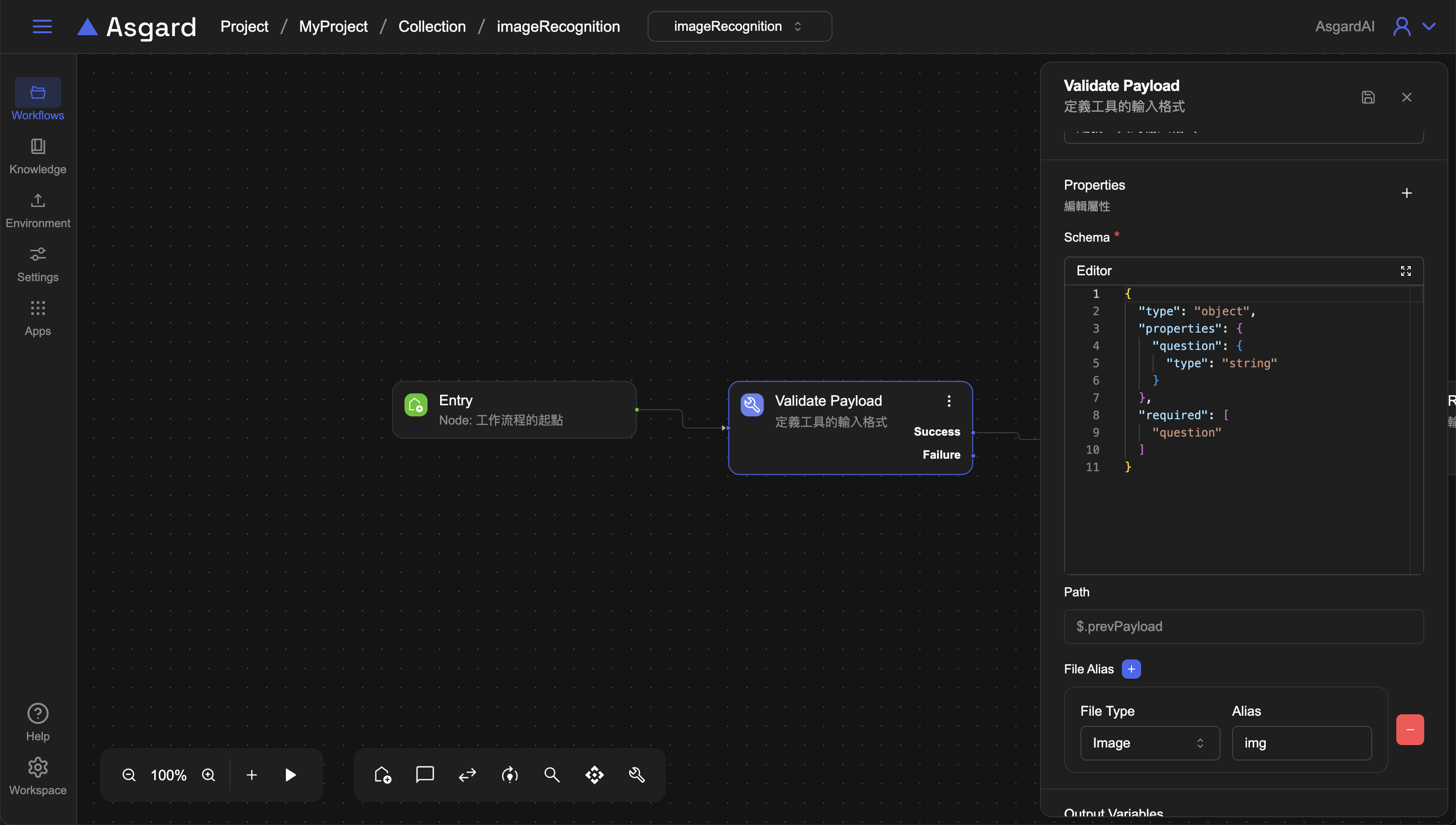
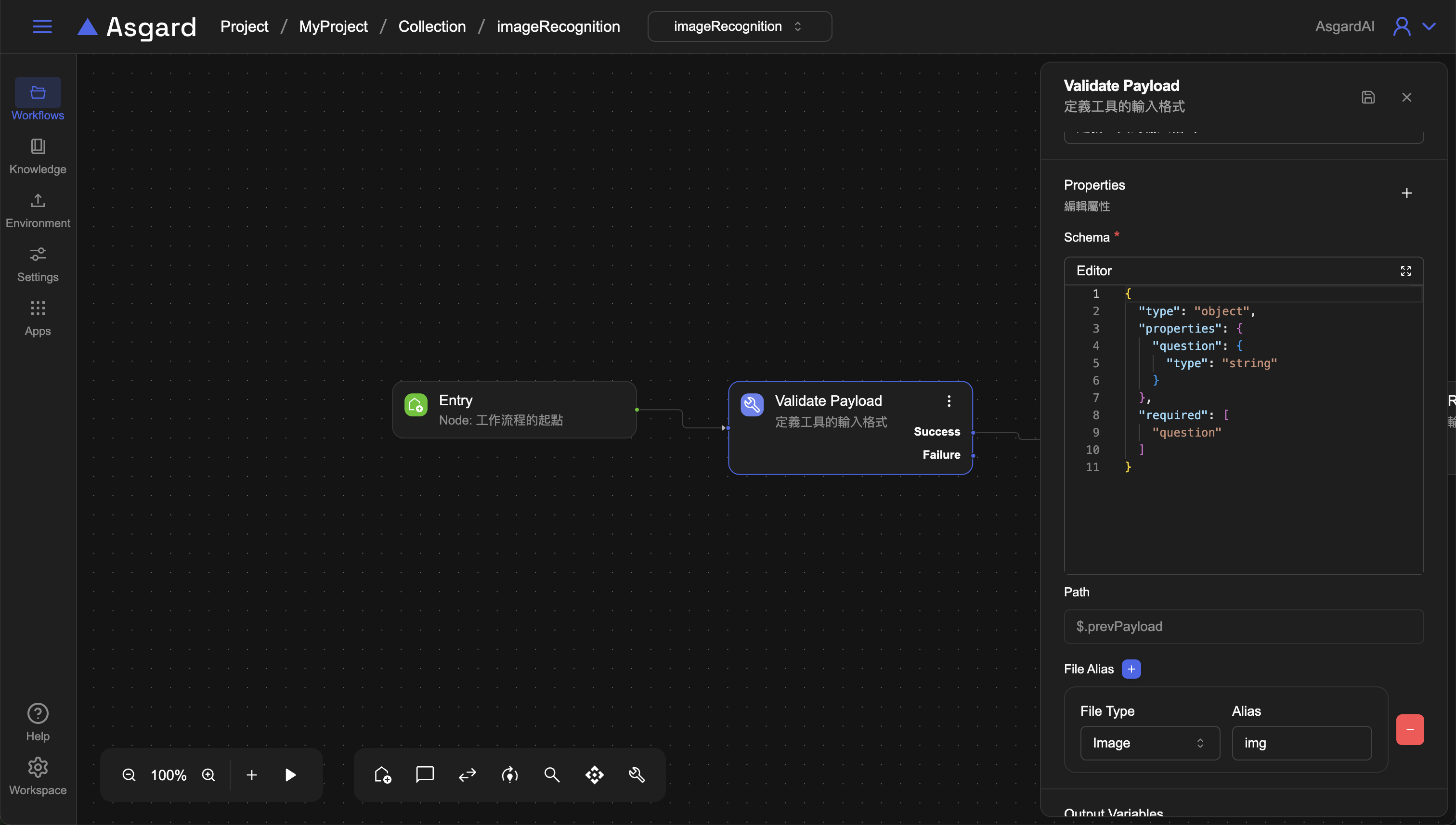
4-1 Validate Payload
在 Schema 輸入需要驗證的 JSON Schema,此處我們需要讓用戶輸入一個問題,因此先用 question。
{
"type": "object",
"properties": {
"question": {
"type": "string"
}
},
"required": [
"question"
]
}
詳細 JSON Schema 寫法,請參考JSON Schema
- File Alias: 由於需要用戶上傳圖片辨識,此處需要新增一個 file,
File Type請選擇image,Alias 可以自訂,範例使用 img 作為別名。
4-2 LLM Completion
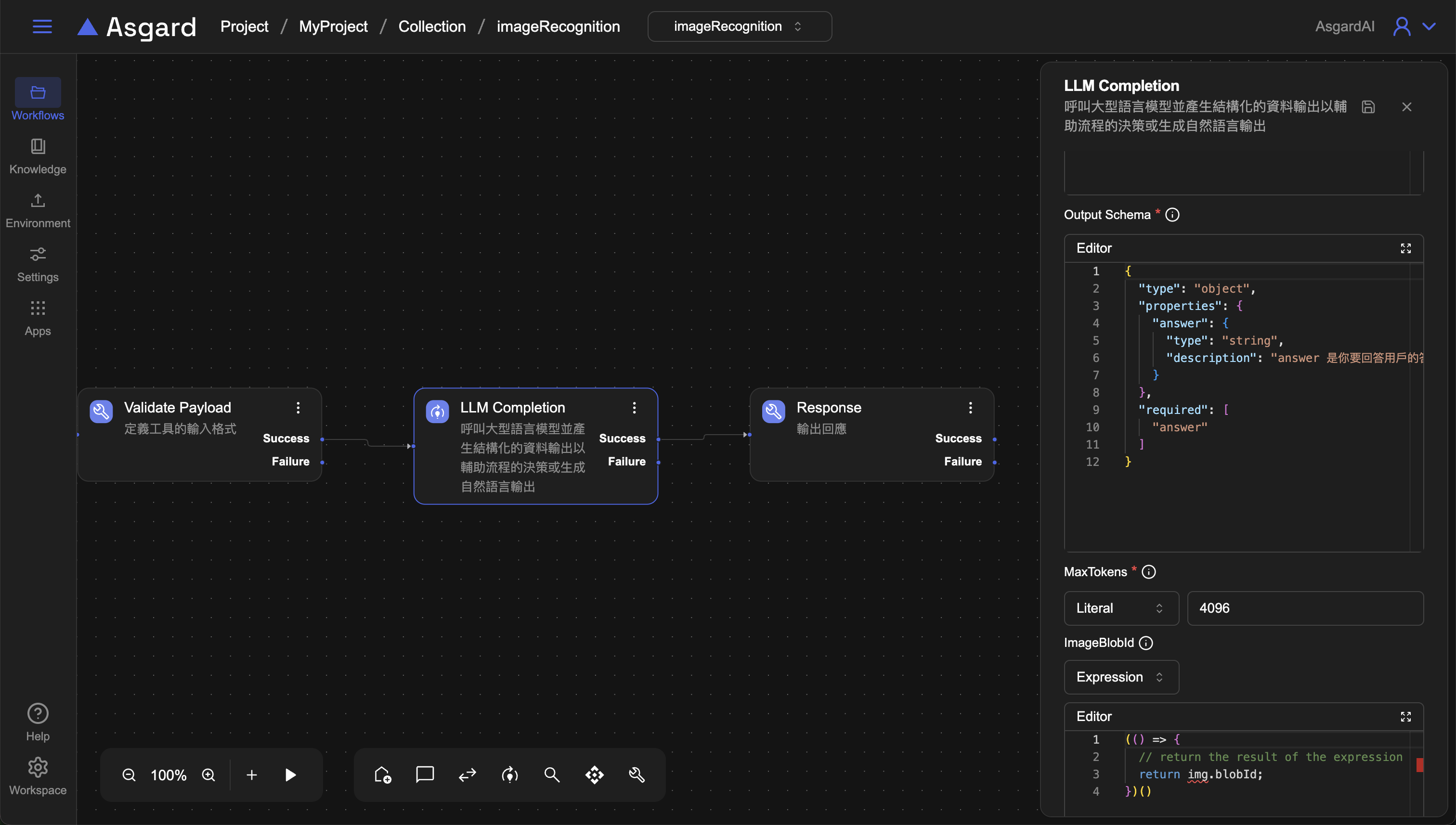
在 Completion Model 選擇已經建好的 model 或點擊 Add 新增 model(注意模型需要支援image),提示語 Prompt 的部分選擇 Template(Advance),並提示 LLM 觀察圖片並回答用戶輸入的問題。
你是影像辨識的助手,負責觀察使用者上傳的圖片,並且回答使用者的問題。
* 這是使用者的問題: '{{{prevPayload.question}}} '
Output Schema: 將 LLM 的回答存到 answer
{
"type": "object",
"properties": {
"answer": {
"type": "string",
"description": "answer 是你要回答用戶的答案"
}
},
"required": [
"answer"
]
}
- MaxToken: 設定消耗 Token 上限為必��填。
- ImageBlobId: 請選擇
Expression並輸入以下範例。
(() => {
// return the result of the expression
return img.blobId;
})()
可以到模型供應商查詢模型支援的功能,以 OpenAI 為例,gpt-4o 可以支援 input image。
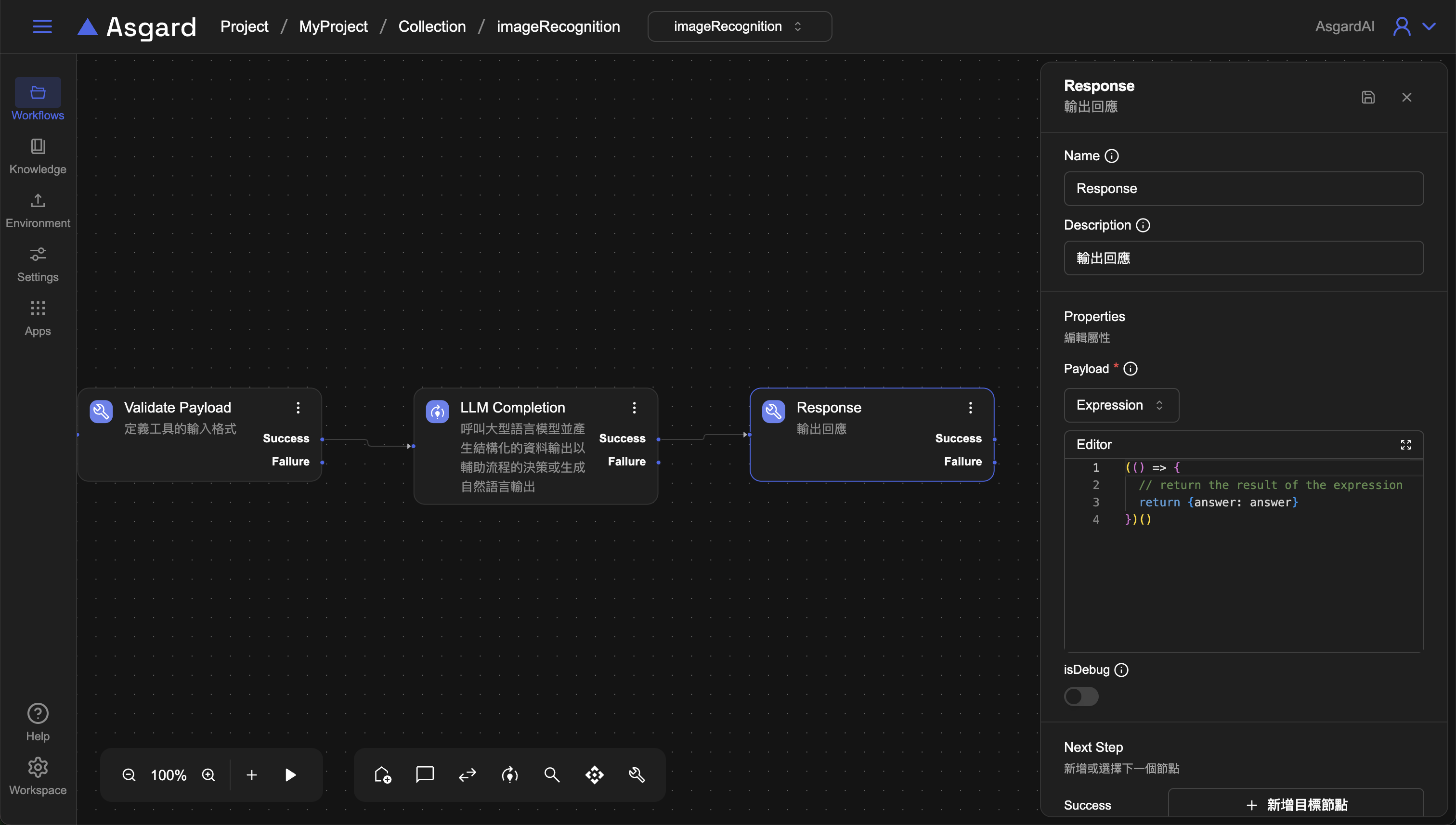
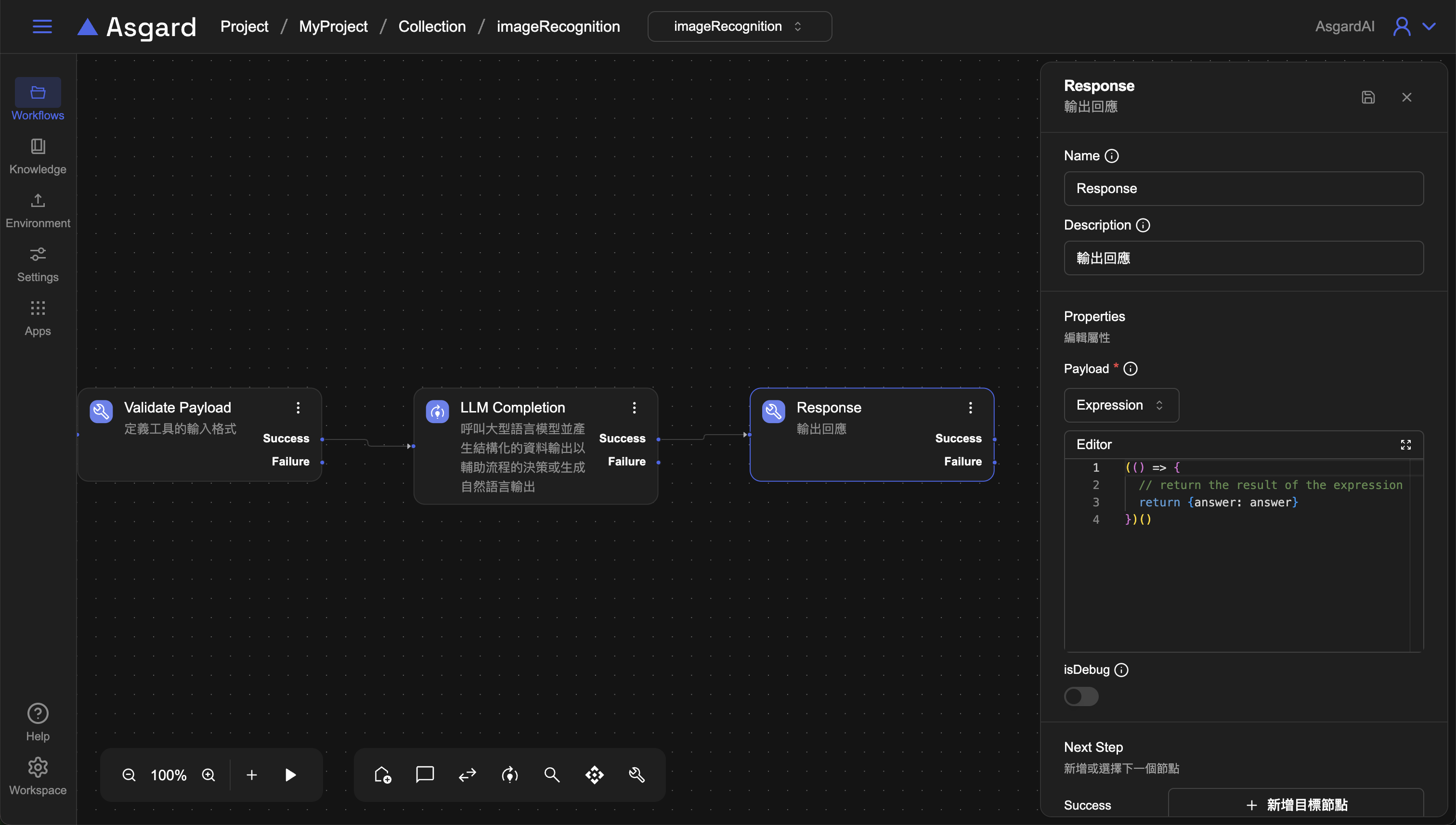
4-3 Response
利用Payload屬性輸出與訊息對應的結構化資料。選擇Expression並填入以下範例。
(() => {
// return the result of the expression
return {answer: answer}
})()
4-4 預覽
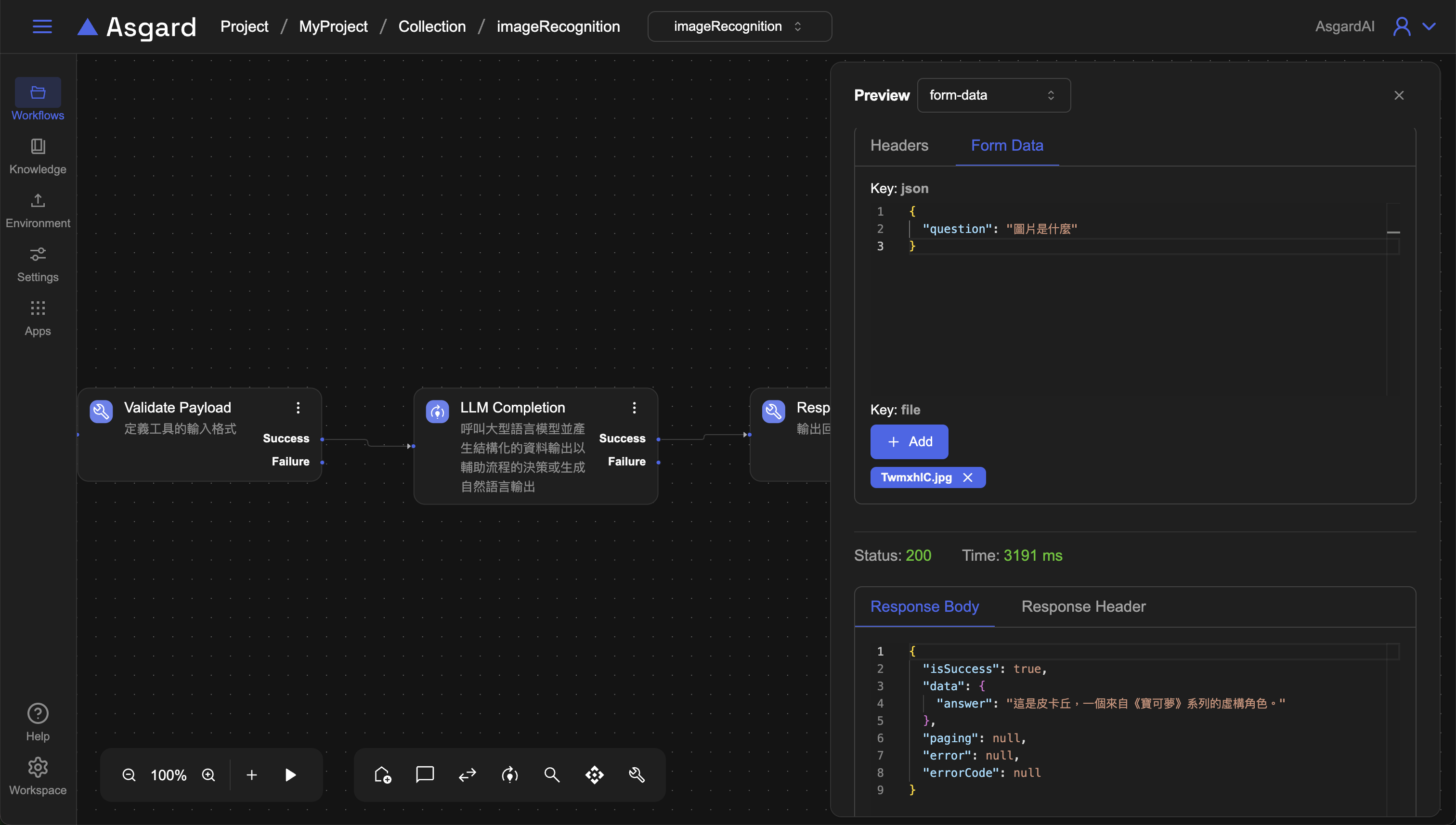
預覽 Automation Tool,點擊 preview 來實際存取該 API 測試,類型請選 Form-data,在 Form data 的地方,可以看到剛剛規定需要輸入的 question,此處輸入問題後並點擊底下的 Add 上傳一張圖片,上傳後點擊 Send。底下 Response Body 可以成功讓 LLM 辨識圖片並描述該張圖片內容作為 answer:
"answer":"這是皮卡丘,一個來自《寶可夢》系列的虛構角色。"